Antifragile system
https://www.amazon.com/Hands-Software-Architecture-Golang-applications-ebook/dp/B079X2RGKQ
How to architect an anti-fragile system
- Reliability metrics
- Engineering reliability—architecture patterns for ensuring high-availability
- Verification of reliability—ensuring that the system is tested for resiliency through unit tests, integration test, load tests, and chaos-testing
- Building resilience for dependencies
- Datacenter resilience
Reliability metrics
Dynamic metrics
- Mean Time To Failure (MTTF): the time interval between the successive failures. An MTTF of 200 means that 1 failure can be expected every 200 time units
- Availability: If a system is down an average of 4 hours out of 100 hours of operation, then its availability is 96%.
- Service-level agreements (SLA): These are definitions on how well the system is performing. An example of such a metric is API response latency
- Robustness: The extent to the system tolerates unexpected inputs, scenarios, and problems.
- Consistency and precision: The extent to which software is consistent and gives results with precision
Static metrics
These metrics typically measure the code quality and provide an indication of its reliability.
- Cyclomatic complexity: This is a quantitative measure of the complexity of a program. It is derived from the number of linearly independent paths through a program's source code.
- Defect amount and rate: How many open defects are there against the production system? How many bugs are created with 100 lines of code?
- Testability: The amount of effort required to test the system and ensure that it performs its intended functions.
- Maintainability:: The effort required to locate and fix an error during regular maintenance.
Engineering reliability
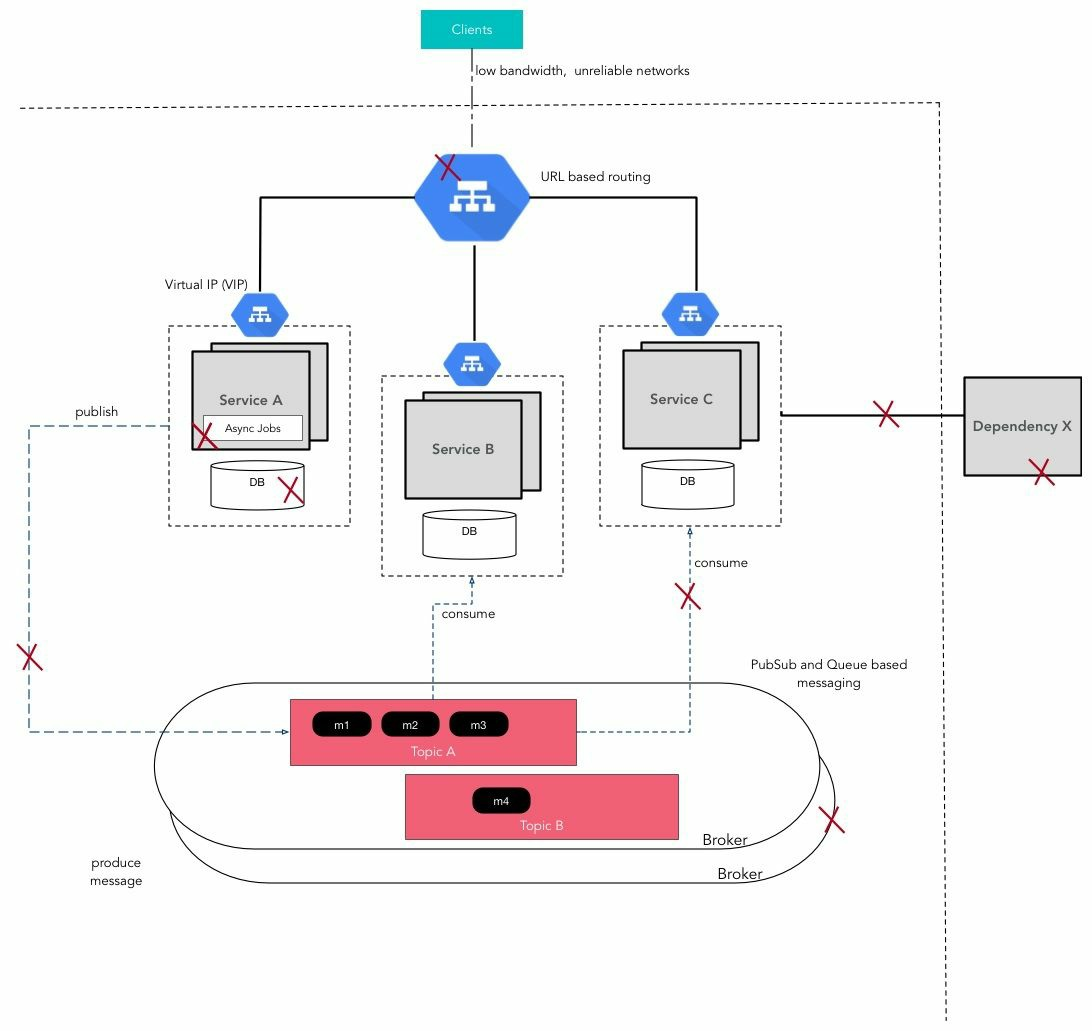 Problems:
Problems:
- A service may go down either during the the service of a request from a client
- The service may go down because the machine went down or because because there was an uncaught exception in the code.
- A database hosting persistent data may go down. The durable storage might get corrupted. The DB can crash in the middle of a transaction!
- A service may consume a message from the broker but may crash just before acting on it.
- A dependent external service may start acting slow or start throwing errors.
- The network link between two services may go down or be slow.
Hotspot
Every sevice has a breaking point. If the load exceeds this, the service can become unreliable.
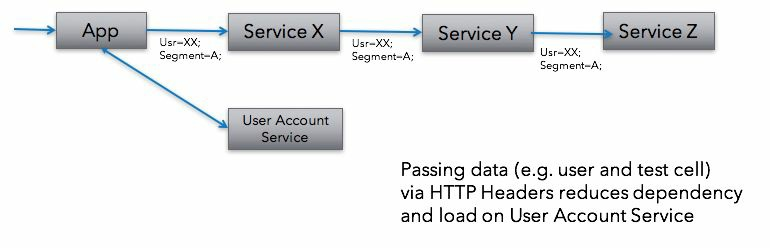
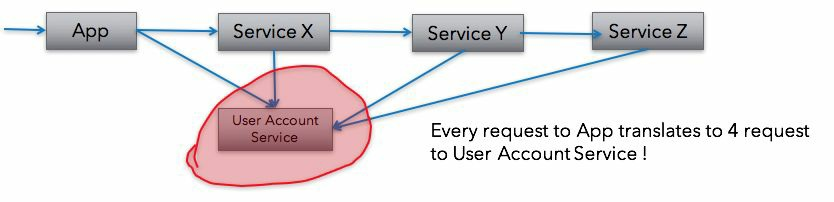 One solution to the problem is to carry the required data in every service call, like so
One solution to the problem is to carry the required data in every service call, like so
Throttling
Every service is built and deployed with a specific load capacity in mind. If the processing requests exceed this capacity, the system will fail.
There are two options in terms of solving for a high load:
- When the load is genuine, we increase capacity (the number of servers, service instances, network capacity, DB nodes, and so on) to meet the increased traffic.
- When the load is not genuine/business critical, analyze and control the requests, that is, throttle the request.
Throttling strategies:
- Rejecting requests from an individual user whose crossed the assigned quota
- A common way to implement throttling is to do it at the load-balancer level like Nginx
Reliability verification
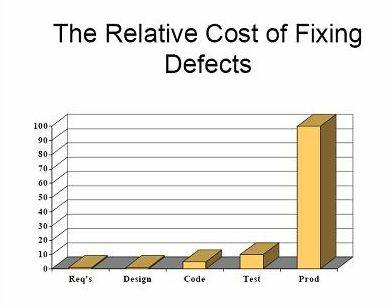
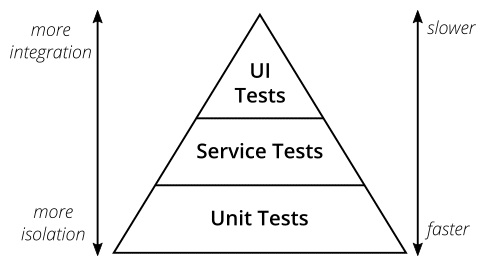
The key to finding bugs for a service early is having a regression test suite that can be run early and often ensure quality
The constituents of a regression suite include the following:
- Unit tests
- Integration tests
- Performance tests
Unit tests
The scope of unit testing is to test individual modules(classes/functions) The unit test need two accompanying framework:
- Mock/Stub: When testing a specific module, we need other downstream-dependent components to fulfill behavior. Sometimes calling the live component may not be possible (sending an email via a live email service may not be an option, as we want to avoid annoying customers with spam). We should either mock or stub out the dependent modules so that we can exercise the code through various interesting paths.
- Automation: These should be automated so that they can be run on every commit, thereby solving bugs at the earliest possible stage
TDD encourages taking this to the next level by writing unit tests even
before writing code.
Integration test
Once a service has been verified in isolation, it should be tested along with its dependents in a specific integration or stage environment
Since these tests are higher up in the test pyramid, they focus on more business-related interactions.
So, unit tests are more like this:
Integration tests are more like the following:
UI test
- The test cases are derived from the requirements (user stories) and try out all scenarios that the user would experience on the real app.
- These tests are generally run with the backend services in the stage environment.
- There are many frameworks, such as Selenium, that help in automating these tests
Performance tests
- Latency: The application should respond quickly, as described in the latency SLAs for various operations
- Scalability: The application should handle the maximum prescribed user, and yet maintain the latency characteristics described previously.
- Stability: The application should be stable under varying load and load ramps
There are various types of tests that ensures the preceding goals:
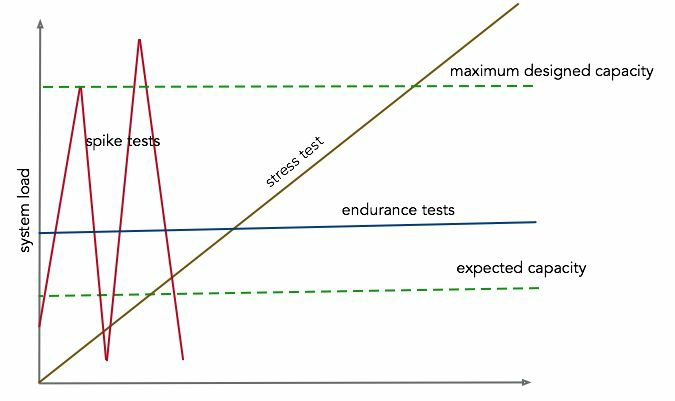
- Load/Stress tests: These check the application's ability to perform under various levels of loads (requests per second). The objective is to measure latency and the stability of the system under various conditions of load or stress.
- Volume-testing: Under Volume-testing, a large amount of data is populated in a database and the overall software system's behavior is monitored.The objective is to check the software application's performance under varying database volumes. These tests bring out issues with database modeling, such as an index not created on often-queried columns.
- Scalability Tests: The objective of scalability testing is to determine the software application's effectiveness in scaling-up to support an increase in the user load.
- Endurance testing: This test is performed to ensure that the software can handle the expected load over an extended period of time.
- Spike testing: It tests the software's behavior for sudden large spikes in the load. Generally,steep ramps in load can bring out issues that are different from endurance tests (constant load).
Chaos-engineering
- Instead of waiting for things to break at the worst possible time, chaos-engineering believes in proactively injecting/crafting failures in order to gauge how the system behaves in these scenarios.
- The aim is to identify weaknesses before they manifest in surprising aberrant behavior
Process:
- Define normal behavior via a set of metrics—these could be CPU/memory utilization, response time, or error rates.
- Introduce chaos by simulating failure events, such as server crashes, disk malfunctions, or network partitions.
- Verify the hypothesis that the control and experimental group both show normal behavior.
Some of the tools (monkeys)
Chaos Monkey: Randomly disables production instances to make sure that redundancy and failure-tolerance are working as expected.
Latency Monkey: Induces artificial delays and network partitions between client services and between services.
Conformity Monkey: Finds instances that don't adhere to best practices and shuts them down.
Chaos Gorilla: Similar to Chaos Monkey, but simulates an outage of an entire Amazon availability zone, thereby verifying cross-geo high-availability.
Depedencies
In big software systems, such dependency graphs can get quite complicated, as shown here:

Cascading failures
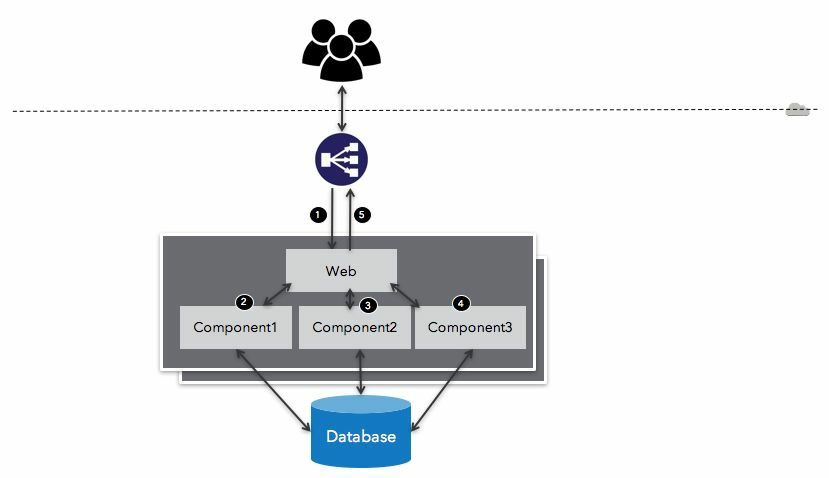
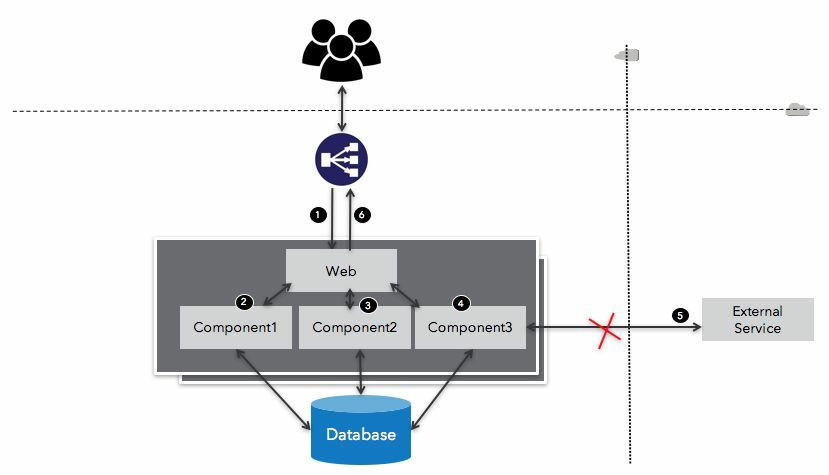
Dependency resilience
- Be nice to broken service: If the dependent service is down, we should not bombard it with more requests, thus allowing it time to recover
- Gracefully degrade: Our clients should get a clear and timely error message
- Provision monitoring/alerts: We should be able to monitor the health of our dependents in the same way as we do monitoring of our own systems.
- fallback:
- Queue: If the operation calls for the dependency to do some work, and the output of the work is not necessary for the request to be completed, then the request can be put in a durable queue for retry later. One example is sending an email for Booking. If the Email service is down, we can queue a request for the Email in something such as Kafka.
- Cache: If a response is needed from the dependent, another strategy is to cache data from previous responses. To keep the cache from exploding in terms of space requirements, strategies such as Least-Recently Used (LRU) can be employed
Database-level reliability
Datacenter-level reliability
- What happens if the entire datacenter goes down? To be prepared for this eventuality, you need to run your application cluster in more than one datacenter
- Ensure that both deployments are in sync in terms of data. Building such architectures is typically under the purview of business continuity planning (BCP) and disaster recovery (DR).
Consistency
- Weak: This is a best-effort consistency. There are no guarantees on the durability of the data. One example is cache stores—they are rarely replicated across datacenters. Applications that are well-suited to this model include video streaming and VOIP.
- Eventual: there is no guarantee that a read immediately after a write will see the new value, but eventually all the deployments get the new value and reads would be consistent across.
- Strong: This is the highest level of consistency. All reads, irrespective of the location, immediately reflect a committed write.