TiDB
What is TiDB?
is a distributed HTAP database compatible with the MySQL protocol.
HTAP (hybrid of OLTP and OLAP) is a term that describes a database architecture that breaks down the wall between transactional and analytical data workloads. The goal is to give businesses real-time analytics and thus enable real-time decision-making
Difference between OLAP and OLTP:
- if you are doing analytics (ex. aggregating historical data) use OLAP
- if you are doing transactions (ex. adding/removing orders on an e-commerce cart) use OLTP
Features
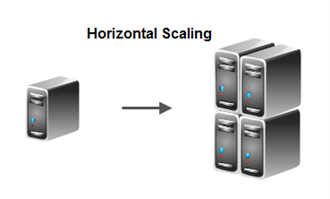
Horizontal scalability: TiDB provides horizontal scalability simply by adding new nodes. Never worry about infrastructure capacity ever again.
MySQL compatibility: Easily replace MySQL with TiDB to power your applications without changing a single line of code in most cases and still benefit from the MySQL ecosystem.
Distributed transaction: TiDB is your source of truth, guaranteeing ACID compliance, so your data is accurate and reliable anytime, anywhere.
Cloud Native: TiDB is designed to work in the cloud -- public, private, or hybrid -- making deployment, provisioning, and maintenance drop-dead simple. TiKV the storage engine of Tidb is now a part of cloud native computing foundation
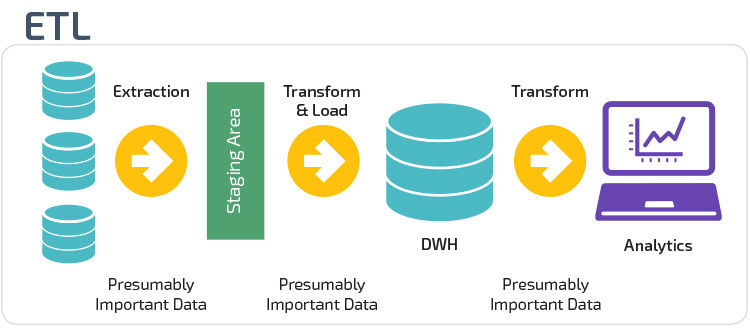
No more ETL: ETL (Extract, Transform and Load) is no longer necessary with TiDB's hybrid OLTP/OLAP architecture, enabling you to create new values for your users, easier and faster.
High availability: With TiDB, your data and applications are always on and continuously available, so your users are never disappointed.
gathers metrics in Prometheus/Grafana: With TiDB, rather than retaining the metrics inside the server, a strategic choice was made to ship the information to a best-of-breed service. Prometheus+Grafana is a common technology stack among operations teams today, and the included graphs make it easy to create your own or configure thresholds for alarms.
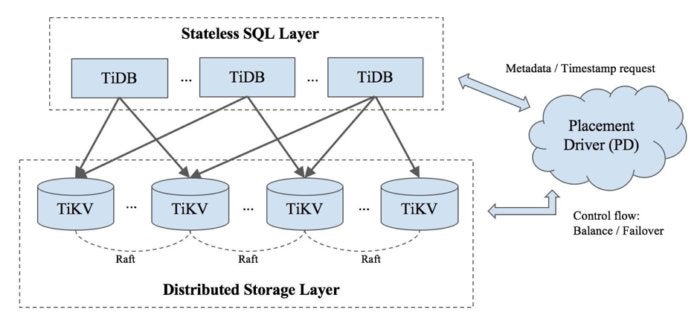
Components
- TiDB: A stateless SQL layer that is MySQL compatible, built in Go.
- TiKV: A distributed transactional key-value store, built in Rust. (TiKV recently became a Cloud Native Computing Foundation project.)
- TiSpark: An Apache Spark plug-in that connects to TiKV or a specialized, columnar storage engine (something we are working on... stay tuned).
- Placement Driver (PD): A metadata cluster powered by Etcd that manages and schedules TiKV.

Use Case
- MySQL Scalability:
- Considering how to replicate, migrate, or scale your database for extra capacity
- Looking for ways to optimize your existing storage capacity
- Getting concerned about slow query performance
- Researching middleware scaling solutions or implementing a manual sharding policy
- HTAP Real-Time Analytics
- TiDB breaks down the wall between OLTP and OLAP by decoupling its compute layer and storage layer, and using different stateless SQL engines (TiDB and TiSpark) for different analytics tasks. Both engines connect to the same persistent data store (TiKV), making real-time analytics and decision-making a natural product of the system
When you should use TIDB
- RDBMS is becoming the performance bottleneck of your backend service
- The amount of data stored in RDBMS is overwhelming
- You want to do some complex queries on a sharding cluster
- Your application needs ACID transaction on a sharding cluster
Test and Benchmark
- Suppose that we have an employee database with tables like this running on a local mysql server
- there are nearly 3 million records in
salariestable which is distributed over 10 partitions and 300 thousand records inemployeestable so we can test how well TiDB perform over MySQL on a large dataset
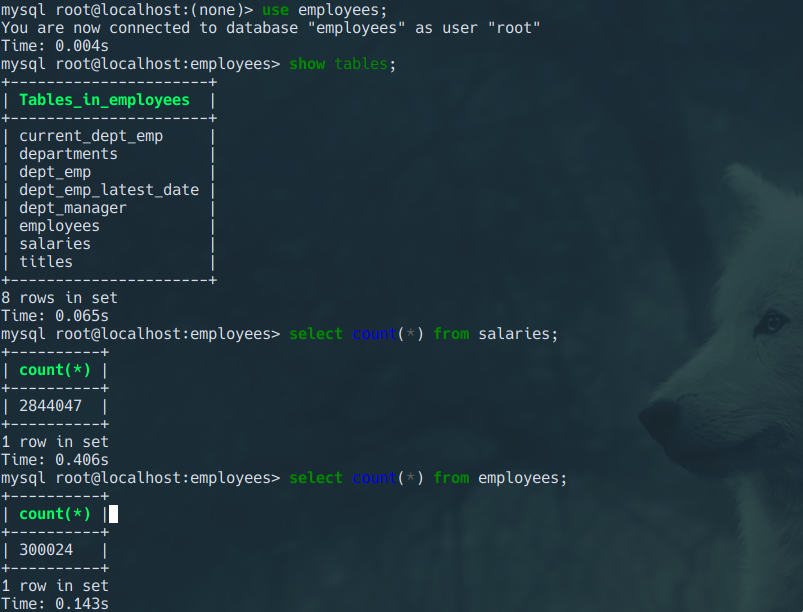
Do a simple query
With MySQL
 Benchmark with go
Benchmark with go

With TiDB
 Benchmark with go
Benchmark with go

Do a complex join query
With MYSQL
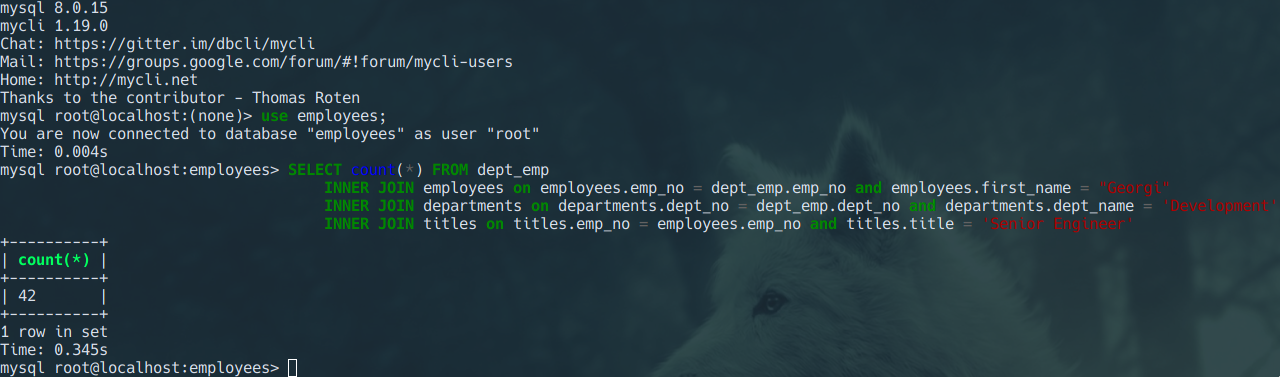 Benchmark with go
Benchmark with go

With TiDB
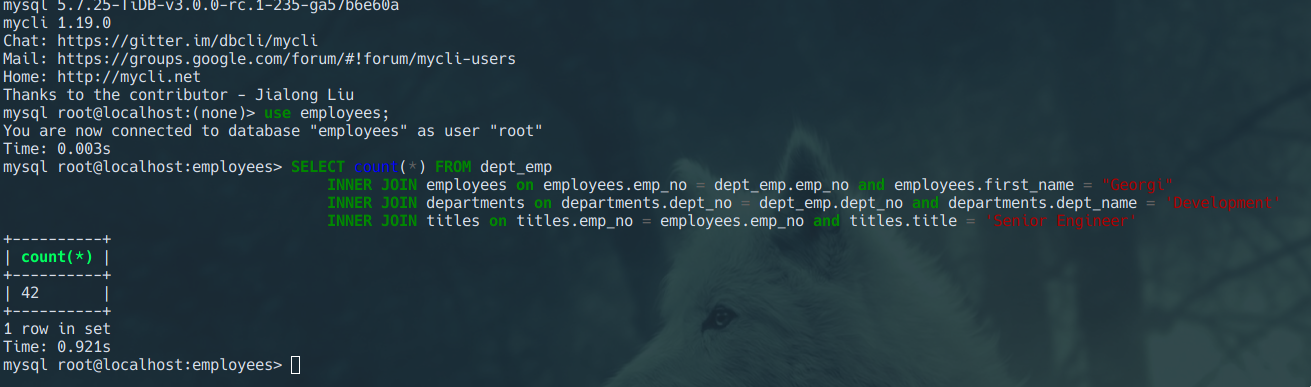 Benchmark with go
Benchmark with go

| Database | Simple Query | Complex Join Query |
|---|---|---|
| MySQL | 0.9 sec/op | 0.327 sec/op |
| TiDB | 1.3 sec/op | 0.812 sec/op |
- From the result we see that MySQ outperform TiDB when the data set is large
Some serious benchmark results i gathered from the internet
TPS - Transacitons per second QPS - Queries per second

So the test result shows that when concurrency (controllable in middlewares) is not quite high, MySQL outperforms TiDB a lot but when concurrency is higher, the throughput of MySQL reduce obviously.
It turns out that TiDB is not that good as what they claim in many ways.
Besides there are several other issues you might know:
- Data writing operations that create primary keys continuously will cause pretty high IO on some disks. As TiKV uses range-partition for the primary key, the continuous primary keys will be in the same region, causes hot spot issue. This makes it difficult to modify business that has a lot incremental sequence primary keys to be adjusted
- No local indexing: TiDB has not support B-tree indexing, so it can only use global indexing. Any record change may cause the cross-server change of indexes, this may also cause distributed transaction submitted when there is only one record changes
- Even TiDB uses Percolator mechanism to transform the 2-pc into two phases of synchronous and asynchronous. This may still cause serious net delay due to the lock conflicts.
- TiDB’s region partitioning and balancing will cause backend disks pressure burst. In the test I’ve detected many jump from peak to trough, disks usage is pretty high maybe it triggered some auto splitting or merging mechanism.
Answer to How does TiDB compare with MySQL? - Quora
Conclusion
- TiDB might be an interesting product in China that can fully ‘support’ distributed OLTP, but to be an enterprise-ready product,it still has a long way to go. Also, it’s rarely seen for a database using LSM tree for OLTP, there may have some problems.
A lead engineer at pinterest:
We intentionally ran away from auto-scaling newer technology like MongoDB, Cassandra and Membase, because their maturity was simply not far enough along (and they were crashing in spectacular ways on us!). I still recommend startups avoid the fancy new stuff — try really hard to just use MySQL. Trust me. I have the scars to prove it. MySQL is mature, stable and it just works. Not only do we use it, but it’s also used by plenty of other companies pushing even bigger scale
Quote from Sharding Pinterest: How we scaled our MySQL fleet - Pinterest Engineering - Medium