Managing resources
These are the key contents I take from this book: https://www.oreilly.com/library/view/cloud-native-devops/9781492040750/
Scheduler decide where to run a given Pod. A Pod that needs 1GiB of memmory cannot be scheduled on a node with only 100 MiB of free memory.
Similarly, the scheduler has to be able to take action when a greedy Pod is grabbing too many resources and starving other Pods on the same node
Resource unit
- millicpus
- mebibytes (MiB)
Kubernetes allows resources to be overcommitted; that is, the sum of all the resource
limits of containers on a node can exceed the total resources of that node because this is kind of gamble, most of the time, most containers will not need to hit their resource limits.
Managing the Container Life Cycle
Container often get into a stuck state, where the process is still running, but it’s not serving any requests. Kubernetes needs a way to detect this situation
Liveness Probes
health probes can be used by a container orchestration system to determine when an application needs to be restarted
a health check that determines whether or not the container is alive.
Liveness probes tell Kubernetes whether the container is working properly. If a container’s liveness probe fails, it will be killed and restarted.
- HTTP server container:
- tcpSocket :
You can also run an arbitrary command on the container, using an exec probe:
Readiness Probes
readiness probe determines when an application is ready to serve user requests
Readiness probes tell Kubernetes that the container is ready and able to serve requests. If the readiness probe fails, the container will be removed from any Services that reference it, disconnecting it from user traffic.
A container that fails its readiness probe will be removed from any Services that match the Pod. no traffic will be sent to the Pod until its readiness probe starts succeeding again.
Namespaces
Namespaces are a way of logically partitioning your cluster. We can create one namespace per application, or per team
Resource Quotas
Restrict the resource usage of a given namespace
Vertical Pod Autoscaler
Add on pod autoscaler help you work out the ideal values for resource requests. It will watch a specified Deploymentand automatically adjust the resource requests for its Pods based on what they actually use
Cleaning Up Unused Resources
Using owner metadata

The owner metadata should specify the person or team to be contacted about this resource. This is useful anyway, but it’s especially handy for identifying abandoned or unused resources.
Cleaning up completed Jobs
Kubernetes Jobs are Pods that run once to completion and are not restarted. However, the Job objects still exist in the Kubernetes database. Once there are a significant number of completed Jobs, this can affect API performance
Keeping Your Workloads Balanced
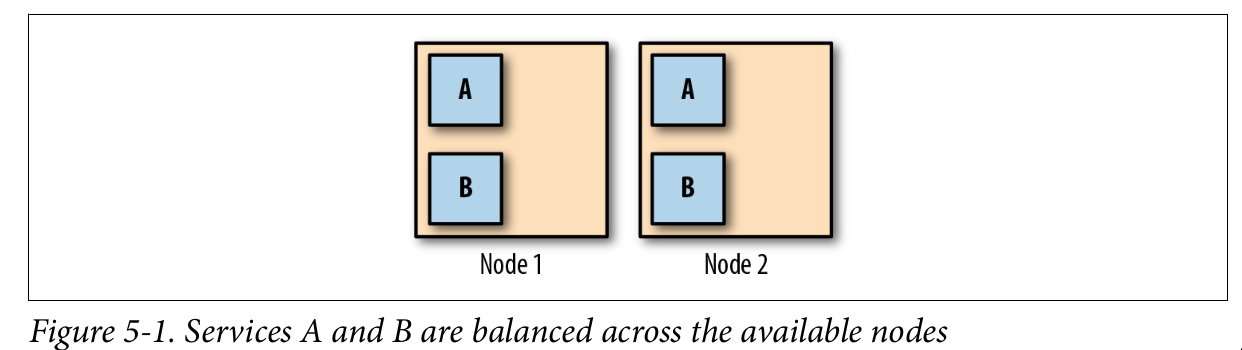
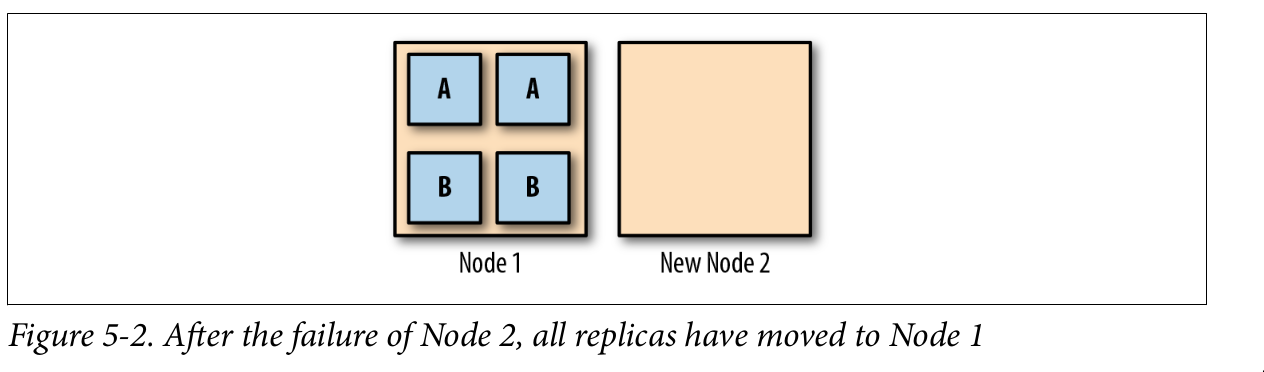
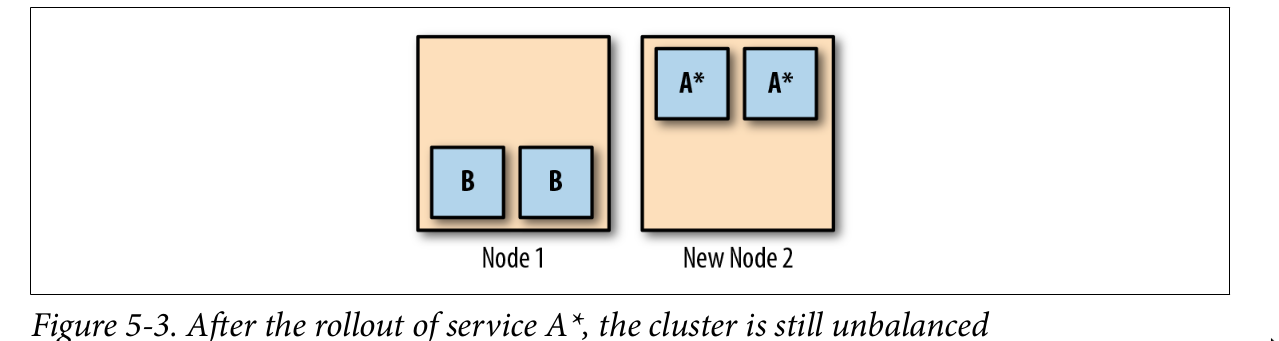
No high availability. Run this tool Descheduler every so often, as a Kubernetes Job. It will do its best to rebalance the cluster by finding Pods that need to be moved, and killing them